-

ARS 在版块 赛事讨论 中发起了话题 专家大战模型: 我们该如何对车手进行排名? 当前情况统计

谁是更加伟大的车手:奈杰尔·曼塞尔还是埃里奥·德·安吉利斯?专家团都一致选择了曼塞尔。从衡量成功的原始数据——获胜、冠军等等——也是显而易见的倾向于曼塞尔。然而,任何一种现有的衡量车手级别的数学模型都会选择安吉利斯。

这是一个对比非常强烈的例子,但毫无疑问这不是唯一一个在F1中车手职业生涯成就和车手(作为队友)相互之间的数据存在冲突的案例。这种案例表明在比较车手的时候选择哪种衡量指标非常重要,并且也说明了专家和模型的取向会不一样。
在我开始写这篇博文的时候,我已经完成了一个庞大的分析项目,最终成文《基于模型评级的F1历史上最佳车手》。在评价车手(相比于评价其他体育运动的运动员)最根本的问题在于要考虑车手所驾驶的不同的赛车——除了车手之间是队友的情况(就算是这样,比较也可能会非常复杂),这使得车手之间的直接对比变得不可能。在F1,车队的表现差异远远大过于车手的表现差异,这意味着传统衡量成功的指标(比如获胜次数,积分)在衡量车手的表现时会不可靠。因此,需要使用定量模型(Quantitative models)来推断各种客观排名。
在我开始开展我的工作的时候,只有一种模型适用于F1(Eichenberger&Stadelmann, 2009)。我觉得仍然有很大的改进空间,所以我提出了我自己的模型(Phillips, 2014),并产生了很多新的观点以及一个有着更好表面效度的车手层级。
近期,一个新的模型得到发表(Bell et al., 2016),它和本博文无关,但是它也是为了在F1中隔离车手和车队的表现。这意味着目前有三个同行评议的模型。每种模型都是为了对车手和车队进行排名的完全客观方法。通过一组数据(比如历史比赛结果)来形成该模型针对这些数据的最佳组合,最终找到代表车队和车手表现的参数值。
模型假设
有意思的是,每种模型都有一些稍微不同的基本假设。其中包括这个模型采用了哪些输入,它们在数学上是如何关联的,模型的复杂度,以及模型的输出。多种模型的存在使得我们理解不同的假设如何影响相对排名以及基本模型结构的排名可靠性是极其有价值的。每种模型的属性归纳如下表所示:
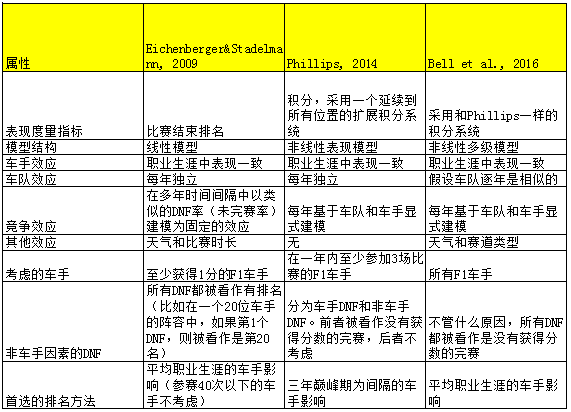
第一种模型和后面两种模型的主要区别是它采用了完赛排名而不是积分来作为表现衡量指标。在一个线性模型中使用完赛排名会引入一些潜在的问题。首先,这种模型会对坏结果非常敏感。比如,一个获得过好几次第一名的车手如果有一次获得了第20名(比如DNF),可能会被认为比他那持续获得第三名的队友表现更差。同样的DNF不会影响那些经常处在比赛队伍后面的车手,这意味着在这套模型下,DNF会因车手所在车队的竞争力不一样而对车手的表现造成不一样的影响。其次,这种模型会造成地板和天花板表现效应 — 那些处在队伍最前面或者最后面的车手/赛车组合在比赛排名方面基本没有什么变化。非线性表现衡量指标可以解决此问题,它通过考虑表现衡量指标(积分)中非线性的变化来衡量车手/车队表现。传统的积分系统并未区别非积分区的排名(比如第12名和第15名并未区分),但这可以采用一个我之前所描述的拓展积分系统解决,这也是其他两个模型工作的原理。
第二个关键的区别是对待DNF的方式不同。本博文所采用的模型(Phillips, 2014)一个独特的地方是去掉了非车手DNF(比如机械故障以及技术问题)。这种方式的主要缺点是准备数据极度耗时–我可以保证,我自己都花了好几个星期来做这件事!优点是它有点考虑了坏运气的因素。Bell ea al.在他们的论文中辩称只要有足够多的比赛,运气成分会被稀释。我同意这个理论,但实际上车手经常只有短暂的职业生涯(几十场比赛),或者有非常不幸运的年头。这会造成很难为单独赛季做排名(我之前曾用我的模型做过演示),并且会产生一些奇怪的排名。比如用Bell et al.模型,劳达的排名会很低,部分原因可能是在1985年和普罗斯特的时候遇到了非常糟糕的可靠性问题(14场比赛遇到了10次机械故障)。同时,克里斯蒂安·菲蒂帕尔迪在Bell et al.的模型中是排在最佳车手的第11名,尽管和他表现较差的队友有着各种结果–这是因为他在短暂的职业生涯中比他队友有着更少的机械DNF。反对抛弃机械DNF的观点认为在早期F1保护车子也是车手的一项重要技能,所以机械故障不能被看作是纯粹的坏运气,不过现在情况已经不同了。
Bell et al.模型比较独特的地方是假设车队在不同赛季的表现存在一些关联。其他两种模型则假设车队的表现在每个赛季并无瓜葛。两种方法都有道理。顶级车队更有可能在不同的赛季都保持水准。但是,历史上也有车队在两个赛季表现发生巨大变化的例子。两种假设都值得考虑。
Eichenberger & Stadelmann和Bell et al.模型也考虑到了一些次要因素,比如天气和赛道状况。考虑到模型的过度规格化,特别是很多年仅仅有0到2场雨战,我更倾向于采用一种更为简单的模型结构。不管怎么说,Bell et al.都利用了这种信息来表明车手在雨中以及街道赛的分数会相对更加重要。直觉告诉我们,两种发现都旗鼓相当。
模型排名
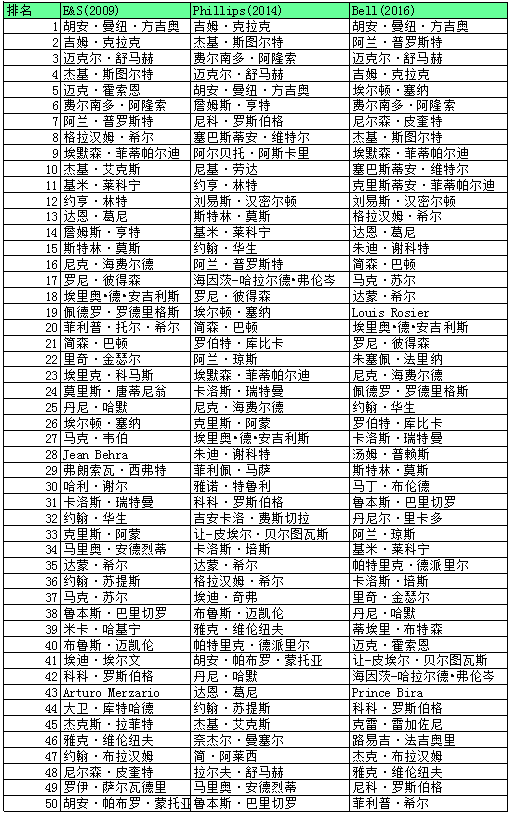
三种模型在很多地方都是采用了类似的预测,但是在其他地方却截然不同。除了给车手进行排名,这些模型还可以用来给历史上最好的车队进行排名。最新的两种模型都确认,在F1的整体表现中,车队的表现比车手的表现占比更多,Phillips模型车队的占比为61%,而Bell et al.模型车队的占比为86%。Eichenberger & Stadelmann模型可能也计算了这一数据,但是并没有在论文中阐述。三种模型评出的前50名车手如下表所示。在某些情况下,两种模型会偏爱一个特定的车手,而其他一种模型并非如此。
统一排名
可以通过组合这三种不同的模型来形成一个统一的排名。基本思想是把这三种模型看作三位有着不同观点的专家。形成统一的排名就算在体育运动之外的领域也作为一个问题来被研究,比如选举政治候选人以及为业务选择最高效的优先次序。形成统一排名最简单的方法就是根据每位候选者的平均排名来创建一个列表。这被称为Borda方法。举个例子,如果一个车手在三个模型中的排名为3,2和6,他的平均排名为3.67。如果另外一个车手的排名为2,1和4,那么他的平均排名为2.33,因此他的排名比另外一位车手要高。可是,有很多人不喜欢Borda方法。它的一个问题是很容易被极端打分所影响。比如一个车手在5个模型均排在第5名,但是如果他只要在1个模型中排在第100名,那么他最终会排在所有6个模型中都排在第20名的车手后面。如果我们把所有的模型都看作同等有效(这就是我们现在的情况),似乎不考虑那个非常独特的排名,而只考虑其余5个模型的统一性会更加合理一点。另外一个相关的问题是Borda方法违反了孔多塞标准,此标准规定如果绝大多数的排名把一位车手放在第1的位置,那么这位车手就应该在统一排名中也处在第1名。
另外一个形成统一排名的算法是Kemeny-Young方法。这个方法的目标是找到一个和任何一个排名差距最小的统一排名列表,它通过 Kendall tau distance作为差距衡量指标。简而言之,它通过检查统一排名中每两位车手之间的相对顺序,并将此相对顺序和各自的排名列表中两位车手的相对顺序进行对比。比如,如果车手A在统一排名列表中在车手B前面,我们计算有多少个模型有着不一致的顺序(也就是说模型中的列表车手B是在车手A前面)。所有的车手之间都会两两进行这样的对比以便计算出所有不一致的数目。
这种方法可以保证符合孔多塞标准,并且还有一些其他的好处。它主要的劣势是为了最终找到最优的统一排名列表需要进行大量的计算。在我们的情况中,这并不难,因为我们所涉及的列表并不长,仅仅只有三个。
使用距离衡量指标,我们可以首先根据三种模型中有多少种两两不一致的情况来检查三种模型列表的相似度。

如上图所示,我们可以看到三种模型列表之间是非常接近的,而最近的两种模型之间相比与E&S(2009)列表之间会稍微更加接近一点。
这三种模型的统一排名列表(也就是和三种列表最为接近的那个)如下所示,三种模型中每种模型的车手排名在一起展示在旁边。
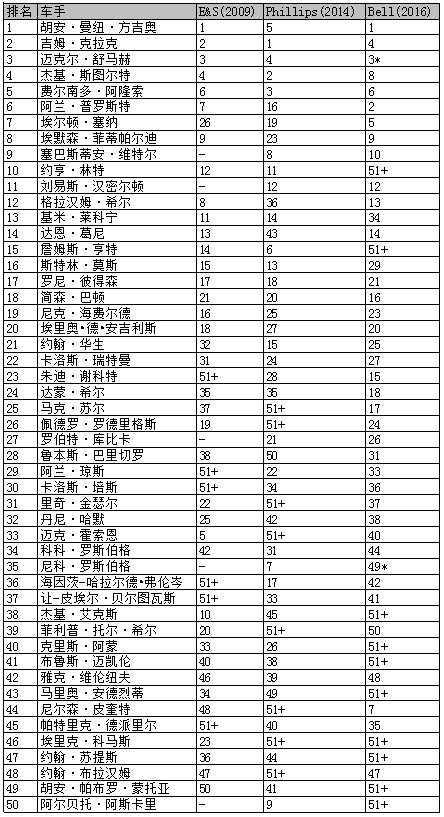
*在Bell et al.模型中,舒马赫排名的推导是忽略了其在2006年以后的比赛结果,并且2010-2012期间将罗斯伯格的队友看作成了一位完全不同的车手。
高估和低估的车手
尽管三种模型并不完全一致,但是它们之间仍然在某些著名车手的排名上保持了一致,不过却和某些专家的意见极为相反。这都是一些值得深思的例子,因为这意味着一些车手可能会被主观标准高估或低估。最近有一个Autosport前40佳车手的排名,它评估了217位F1车手。以下是一些专家与模型最为不一致的情况。杰克·布拉汉姆

杰克·布拉汉姆非常恰当被当作这项赛事的巨擘之一。没有任何人能够完成像他那样依靠他们自己打造的赛车获得锦标赛冠军的壮举。历史上只有四位车手比布拉汉姆获得更多的车手总冠军,他16年的F1职业生涯非常成功。并在43岁的时候赢得了最后一场比赛的胜利。然而,当把他所获得的成功与他的队友进行对比的时候,所有三种模型都认为单单在驾驶技能表现这块,他同时代的车手中有好几个比他更好。他的表现明显不如他的队友葛尼, 林特以及艾克斯。
米卡·哈基宁

哈基宁经常被当作舒马赫最大的对手。马丁·布伦德——一个我非常尊敬的车手——曾与这两位车手都做过队友的他写过一篇文章,阐述了这两位车手的水平是如何的接近。不过我觉得有一件重要的事情需要谨记,布伦德是在舒马赫第一个完整的F1赛季的时候和他是队友,而哈基宁是在他第三个完整赛季的时候与布伦德是队友。因此可以看到布伦德面对的是巅峰时期之前的舒马赫。
模型把哈基宁和舒马赫之间激烈争夺的原因归结于哈基宁的迈凯伦赛车在很多年间都具有更多优势。模型也考虑到库特哈德并不比巴里切罗强,因为哈基宁的水平非常接近库特哈德,但是巴里切罗接近舒马赫的程度则相对较远,这也侧面反应出哈基宁并不如舒马赫。值得一提的是,同样都是他的队友,库特哈德曾以大幅劣势落败于莱科宁,但他在输给哈基宁的时候差距则没有那么大。
奈杰尔·曼塞尔

曼塞尔的驾驶风格观赏性极高。他那孤注一掷的驾车风格经常会导致一些赛道上的戏剧性效果。在专家的眼里,他持续的排在所有F1车手的前20名以内,甚至有时候排在前10。然而,我们很难将这些排名和客观事实保持一致。曼塞尔曾被他的队友德·安吉利斯击败过,并且和科科·罗斯伯格非常接近,专家基本会将这两位车手远远排在曼塞尔后面。不过,模型对曼塞尔的排名是在第50名左右,尽管他有三年的时间(1986,1987,1992)毫无疑问是驾驶着发车格上最好的赛车,但却只获得了一次车手总冠军,相比其排名,这件事情会更加让人印象深刻。
吉尔斯·维伦纽夫

就像是曼塞尔,吉尔斯·维伦纽夫具备所有让一位车手在粉丝和专家中受欢迎的特质:现象级的赛车控制,天生的速度感,雨战技能,以及冒险(几乎疯狂)的决心。然而,结果则不总尽如人意。这些不容错过的特质会掩盖其他地方的问题,比如稳定性以及那些冒险动作并不带来好结果的场合。模型——不在乎雨战结果是否是通过精彩还是无聊的方式获得——在看待事情方面则和专家非常不同。在模型的评估中,维伦纽夫的结果只能说明他是一位好车手,但并不能算是一位伟大的车手。在他们看来,如果维伦纽夫真的那么卓越的话,他本应该可以轻松的击败他的队友们,包括他的主要竞争对手皮罗尼,后者在其F1的职业生涯中被他的每个队友都击败过。
尼克·海费尔德

尼克·海费尔德保持着一些有点令人遗憾的荣誉,他是在没有获胜的车手中登上领奖台次数最多的车手(13次),同时也是在没有获胜的车手中从第二位发车次数最多的车手(183次)。根据模型排名,他应该和克里斯·阿蒙一起被看作是那些未能赢得一场比赛胜利的车手中最好的车手。毫无疑问,两位车手都应该比F1历史上很多赢得过比赛胜利的车手更加出色,两位车手都离胜利十分接近。然而,不知道什么原因,在一些专家眼里,海费尔德甚至没有得到像阿蒙那样的肯定。
在阿蒙的案例中,专家可以利用其他的赛事来评价他,比如Tasman Series,不属于锦标赛范畴的大奖赛,以及耐力赛等。在F1中,阿蒙驾驶的赛车经常足够快到可以让他争取胜利,但车子却缺乏稳定性,当然,这也让他留在了公众的视野中。与之对比的是海费尔德,在与迈凯伦两度失之交臂之后,他主要是为一些F1的中流车队效力。他的比赛成绩持续的比人们对赛车预期的结果要好很多,当然,他有一些特别突出的表现,也有一些特别低迷的表现。他就是有条不紊、持续的得分。在一流车队采用稳定且不冒进的驾驶风格会非常有效(可以去问问阿兰·普罗斯特),但是在其他缺乏竞争力的车队采用这种驾驶风格则永远得不到粉丝的青睐。海费尔德就是典型的例子。
埃里诺·德·安吉利斯

埃里诺·德·安吉利斯是一个明显被遗忘且低估的车手,特别是他在接近巅峰的时候就已经去世,他是围场中最具有魅力的车手之一。当他们在Lotus做队友的时候,德·安吉利斯轻松的就击败了曼塞尔(请参考此文最开始的那张表格)。接着他和塞纳于1985年进行了一场名副其实的对决,尽管在排位赛中以3比13,正赛以3比5,积分榜以33比38的劣势败给了塞纳——这和曼塞尔在法拉利和普罗斯特的战绩不相上下。如果我们考虑大多数专家把塞纳排在第1,曼塞尔排在第15名,那么他们就毫无理由把德·安吉利斯排在前10名以外。事实上,他很少能够排进去前40!
模型相比专家给出了一个非常不一样的结论。换句话说,他们一致认为德·安吉利斯是一位1980年代的伟大车手,并且他更应该排在曼塞尔前面。
埃尔顿·塞纳 & 阿兰·普罗斯特

这里最后一个非常吸引人的例子是塞纳和普罗斯特。自从1997年以来,专家发表在任何一家英文赛车媒体的排名列表都把塞纳评为历史上最伟大车手的第1名或者第2名。并且,这些排名通常是以小幅优势都把塞纳排在普罗斯特前面。在他们于迈凯伦做队友的期间,两位车手在没有计算机械故障的情况下,塞纳在比赛胜场数方面以14场击败了普罗斯特的9场(译注:两位车手在1988年至1989年是队友,普罗斯特两年的胜利场次总数是11场,有两场胜利是由于塞纳遇到了机械故障)。在总的积分方面,普罗斯特以186分击败了塞纳的154分,尽管塞纳在1989年因为运气更差影响到了积分。
有意思的是,这三种数学模型都没有将塞纳或者普罗斯特排在总排名的第1名。另外,三种模型都把普罗斯特排在了塞纳前面,虽然在最近的两种模型中,两者的差距很小。大家可以想象得到塞纳为何被专家们高估的各种原因,包括他那精彩绝伦的驾驶风格(相比而言,普罗斯特的驾驶风格更加低调但非常有效),他所营造的神秘主义色彩,当然还有在他职业生涯接近巅峰的时候就早早去世。
提升空间
模型分析虽然具有明显的定量分析以及客观性的优势,但它们并非没有缺点。作为这项运动经验丰富的观察者,有时候我自己主观的评估都和我自己模型的排名不一致。有些时候,我发现我的主观感受没有扎实的根据,但是在某些特定的情况下,我能够给出充分的理由来阐述为何我觉得模型不够完备。当然,主观感受的问题同样也是有一些经验丰富的观察者和我的观点或者主观推论不太一致——那么我们该相信谁的观点?因此,拥有锐利眼光的专家的主观感觉可以启示我们目前所采用的模型有哪些领域缺失了重要的因素,并且可以在未来得到改善。有一个改善这些模型的一个主意是增加其他的表现指标,比如计时数据,还有比赛结果。在我的论文中,我阐述了我的模型的预测和计时数据非常一致。但是,要通过圈速来推导出表现是有很多的挑战,包括安全车,交通问题,天气状况,轮胎,燃油策略,以及车手选择放弃推进(比如当他们处在舒适的领先位置,或者是因为技术原因)。更进一步说,这些因素在不同的年代都有显著的差异,这也使得寻找一个满意的模型规格变得非常困难。据我所知,目前只有一个通过计时数据的系统来定量的对车手和车队进行排名,这就是做得非常细致的GrandPrixRatings系统。然而,这并不是一个完全客观的模型,因为每年的顶尖车手都是由作者事先选定,其他车手以及车队的表现都是相对他们计算出来的。
值得一提的是,这边所考虑的三种模型都没有考虑某些因素,包括车队指令以及车手和赛车之间的相互作用(比如有些车手更加喜欢一些特定的赛车)。这是因为这些因素在1950年的时候根本就无法进行量化,而就算是在当下也无法可靠的进行量化。在车队指令方面,经常很难评估它们所使用的尺度如何以及它们所带来的连锁效应(不管是比赛策略还是对2号车手的鼓励——如果这些指令没作用,为何要去战斗?)。在埃尔顿·塞纳,迈克尔·舒马赫以及费尔南多·阿隆索的情况下,车队指令也许对比赛结果仅有很小的影响,因为他们在大多数比赛中已经知道如何去击败他们的队友。在车手和车队之间的相互作用方面,事实上是不可能将其与格局的变化进行区分。车手只是在这一年不顺利,还是他们不喜欢这台赛车?这两种情景看起来是一样的,并不能容易的进行任何类型的量化区分。
三种模型一个主要的限制在之前的一篇博文中有提到。也就是说,模型没有考虑到车手的表现在职业生涯中会随着年龄以及/或者经验而会产生系统改变。在我的2015年的评估中,我阐述了一些量化年龄效应的前瞻性工作,现在我正在创建一种可以令人满意的新模型,它将考虑这些因素。我的模型中那些不正确的车手排名看起来大多数是由这个因素导致。比如,
尼科·罗斯伯格(他因和年长的迈克尔·舒马赫进行对比而在排名上受益)
约翰·华生(他因与回归的尼基·劳达对比而在排名上受益)(译注:1982赛季,华生在积分榜击败了队友劳达)
海因茨-哈拉尔德·弗伦岑(他因和年长的达蒙·希尔进行对比而在排名上受益)Bell et al.模型针对其中的一种情况做了特殊处理,它把2010-2012年的迈克尔·舒马赫当作了另外一个完全不同的车手(我在之前的博文中也在我模型中做过同样的试验),试图来避免尼科·罗斯伯格成为最顶尖车手之一的问题,但这只是一种临时的解决方案。我和Eichenberger&Stadelmann都探索了包含年龄和经验效应的模型,但是我们仍然需要找到一种合理的规则以改进模型。
很自然,模型开发永远不可能竣工。这是一个循序渐进的过程,没有任何一种模型是完美的。我将继续开发我自己的模型,我相信其他人也会接受这一挑战。这就是在年度赛季回顾之前我想要表达的东西!
参考文献
Eichenberger, R. and Stadelmann, D., 2009. Who is the best Formula 1 driver? An economic approach to evaluating talent. Economic Analysis and Policy, 39(3), pp.389-406.Phillips, A.J.K., 2014. Uncovering Formula One driver performances from 1950 to 2013 by adjusting for team and competition effects. Journal of Quantitative Analysis in Sports, 10(2), pp.261-278.[给我发了一份PDF文档]
Bell, A., Smith, J., Sabel, C.E. and Jones, K., 2016. Formula for success: Multilevel modelling of Formula One Driver and Constructor performance, 1950–2014. Journal of Quantitative Analysis in Sports, 12(2), pp.99-112.
(本文经F1metrics授权翻译,谢绝转载。原文点此。)